|
Kea 3.3.0
|
|
Kea 3.3.0
|
Although the Kea framework and its DHCP programs provide comprehensive functionality, there will be times when it does not quite do what you require: the processing has to be extended in some way to solve your problem.
Since the Kea source code is freely available (Kea being an open-source project), one option is to modify it to do what you want. Whilst perfectly feasible, there are drawbacks:
To overcome these problems, Kea provides the "Hooks" interface - a defined interface for third-party or user-written code. (For ease of reference in the rest of this document, all such code will be referred to as "user code".) At specific points in its processing ("hook points") Kea will make a call to this code. The call passes data that the user code can examine and, if required, modify. Kea uses the modified data in the remainder of its processing.
In order to minimize the interaction between Kea and the user code, the latter is built independently of Kea in the form of one or more dynamic shared objects, called here (for historical reasons), shared libraries. These are made known to Kea through its configuration mechanism, and Kea loads the library at run time. Libraries can be unloaded and reloaded as needed while Kea is running.
Use of a defined API and the Kea configuration mechanism means that as new versions of Kea are released, there is no need to modify the user code. Unless there is a major change in an interface (which will be clearly documented), all that will be required is a rebuild of the libraries.
The core of Kea is written in C++. While it is the intention to provide interfaces into user code written in other languages, the initial versions of the Hooks system required that user code be written in C++. It is no longer the case and there are examples of hooks written for instance in Python but this guide does not document how to do that. All examples in this guide are in C++.
In the remainder of this guide, the following terminology is used:
To illustrate how to write code that integrates with Kea, we will use the following (rather contrived) example:
The Kea DHCPv4 server is used to allocate IPv4 addresses to clients (as well as to pass them other information such as the address of DNS servers). We will suppose that we need to classify clients requesting IPv4 addresses according to their hardware address, and want to log both the hardware address and allocated IP address for the clients of interest.
The following sections describe how to implement these requirements. The code presented here is not efficient and there are better ways of doing the task. The aim however, is to illustrate the main features of user hooks code, not to provide an optimal solution.
Loading and initializing a library holding user code makes use of three (user-supplied) functions:
Of these, only "version" is mandatory, although in our example, all four are used.
"version" is used by the hooks framework to check that the libraries it is loading are compatible with the version of Kea being run. Although the hooks system allows Kea and user code to interface through a defined API, the relationship is somewhat tight in that the user code will depend on the internal structures of Kea. If these change - as they can between Kea releases - and Kea is run with a version of user code built against an earlier version of Kea, a program crash could result.
To guard against this, the "version" function must be provided in every library. It returns a constant defined in header files of the version of Kea against which it was built. The hooks framework checks this for compatibility with the running version of Kea before loading the library.
In this tutorial, we'll put "version" in its own file, version.cc. The contents are:
The file "hooks/hooks.h" is specified relative to the Kea libraries source directory - this is covered later in the section Building the Library. It defines the symbol KEA_HOOKS_VERSION, which has a value that changes on every release of Kea: this is the value that needs to be returned to the hooks framework.
A final point to note is that the definition of "version" is enclosed within 'extern "C"' braces. All functions accessed by the hooks framework use C linkage, mainly to avoid the name mangling that accompanies use of the C++ compiler, but also to avoid issues related to namespaces.
As the names suggest, "load" is called when a library is loaded and "unload" called when it is unloaded. (It is always guaranteed that "load" is called: "unload" may not be called in some circumstances, e.g., if the system shuts down abnormally.) These functions are the places where any library-wide resources are allocated and deallocated. "load" is also the place where any callouts with non-standard names (names that are not hook point names) can be registered: this is covered further in the section Registering Callouts.
The example does not make any use callouts with non-standard names. However, as our design requires that the log file be open while Kea is active and the library loaded, we'll open the file in the "load" function and close it in "unload".
We create two files, one for the file handle declaration:
... and one to hold the "load" and "unload" functions:
Notes:
In some cases to restrict the library loading to DHCP servers so it cannot be loaded by the DDNS server. The best way to perform this is to check the process name returned by isc::dhcp::Daemon::getProcName() static / class method declared in process/daemon.h header against "kea-dhcp4" and "kea-dhcp6" (other values are "kea-dhcp-ddns" and "kea-netconf"). If you'd like to check the address family too it is returned in DHCP servers by isc::dhcp::CfgMgr::instance().getFamily() declared in dhcpsrv/cfgmgr.h with AF_INET and AF_INET6 values.
"multi_threading_compatible" is used by the hooks framework to check if the libraries it is loading are compatible with the DHCPv4 or DHCPv6 server multi-threading configuration. The value 0 means not compatible and is the default when the function is not implemented. Non 0 values mean compatible.
If your code implements it and returns the value 0 it is recommended to document the reason so someone revisiting the code will not by accident change the code.
To be compatible means:
isc::util::MultiThreadingCriticalSection RAII class.In the tutorial, we'll put "multi_threading_compatible" in its own file, multi_threading_compatible.cc. The contents are:
and for a command creating a new subnet:
Multi-Threading Considerations for Hooks Writers provides more details about thread safety requirements.
Having sorted out the framework, we now come to the functions that actually do something. These functions are known as "callouts" because the Kea code "calls out" to them. Each Kea server has a number of hooks to which callouts can be attached: server-specific documentation describes in detail the points in the server at which the hooks are present together with the data passed to callouts attached to them.
Before we continue with the example, we'll discuss how arguments are passed to callouts and information is returned to the server. We will also discuss how information can be moved between callouts.
All callouts are declared with the signature:
(As before, the callout is declared with "C" linkage.) Information is passed between Kea and the callout through name/value pairs in the CalloutHandle object. The object is also used to pass information between callouts on a per-request basis. (Both of these concepts are explained below.)
A callout returns an int as a status return. A value of 0 indicates success, anything else signifies an error. The status return has no effect on server processing; the only difference between a success and error code is that if the latter is returned, the server will log an error, specifying both the library and hook that generated it. Effectively the return status provides a quick way for a callout to log error information to the Kea logging system.
The CalloutHandle object provides two methods to get and set the arguments passed to the callout. These methods are called (naturally enough) getArgument and setArgument. Their usage is illustrated by the following code snippets.
In the callout
As can be seen getArgument is used to retrieve data from the CalloutHandle, and setArgument used to put data into it. If a callout wishes to alter data and pass it back to the server, it should retrieve the data with getArgument, modify it, and call setArgument to send it back.
There are several points to be aware of:
getArgument must match the data type of the variable passed to the corresponding setArgument exactly: using what would normally be considered to be a "compatible" type is not enough. For example, if the server passed an argument as an int and the callout attempted to retrieve it as a long, an exception would be thrown even though any value that can be stored in an int will fit into a long. This restriction also applies the "const" attribute but only as applied to data pointed to by pointers, e.g., if an argument is defined as a char*, an exception will be thrown if an attempt is made to retrieve it into a variable of type const char*. (However, if an argument is set as a const int, it can be retrieved into an int.) The documentation of each hook point will detail the data type of each argument.In all cases, consult the documentation for the particular hook to see whether parameters can be modified. As a general rule:
CalloutHandle::setArgument to update the value in the CalloutHandle object.Note: This functionality used to be provided in Kea 0.9.2 and earlier using boolean skip flag. See The "Skip" Flag (deprecated) for explanation and tips how to migrate your hooks code to this new API.
When a to callouts attached to a hook returns, the server will usually continue its processing. However, a callout might have done something that means that the server should follow another path. Possible actions a server could take include:
To handle these common cases, the CalloutHandle has a setStatus method. This is set by a callout when it wishes the server to change the normal processing. Exact meaning is hook specific. Please consult hook API documentation for details. For historic reasons (Kea 0.9.2 used a single boolean flag called skip that also doubled in some cases as an indicator to drop the packet) several hooks use SKIP status to drop the packet.
The methods to get and set the "skip" or "drop" state are getStatus and setStatus. Their usage is intuitive:
Like arguments, the next step status is passed to all callouts on a hook. Callouts later in the list are able to examine (and modify) the settings of earlier ones.
If using multiple libraries, when the library wants to drop the current packet, the DROP status must be used instead of the SKIP status so that the packet processing ends at that specific hook point.
It is recommended for all callouts to check the status before doing any processing. As callouts can modify the status, it is recommended to take good care when doing so, because this will have impact on all remaining hooks as well. It is highly recommended to not reset the SKIP or DROP status to CONTINUE, even though possible, so that the rest of the loaded hooks and the server can check and perform the proper action.
Some hook points handle special functionality for the server, like pkt4_receive, pkt6_receive, which handle unpacking of the received packet, pkt4_send, pkt6_send, which handle packing of the response packet.
If the hook handles these actions and sets the next step flag to SKIP, it should also perform a check for the SKIP flag before anything else. If it is already set, do not pack/unpack the packet (other library, or even the same library, if loaded multiple times, has done it already). Some libraries might also need to throw exceptions in such cases because they need to perform specific actions before pack/unpack (eg. addOption/delOption before pack action), which have no effect if pack/unpack action is done previously by some other library.
As stated before, the order of loading libraries is critical in achieving the desired behavior, so please read Multiple User Libraries when configuring multiple libraries.
In releases 0.9.2 and earlier, the functionality currently offered by next step status (see The Next step status) was provided by a boolean flag called "Skip". However, since it only allowed to either continue or skip the next processing step and was not extensible to other decisions, setSkip(bool) call was replaced with a setStatus(enum) in Kea 1.0. This new approach is extensible. If we decide to add new results (e.g., WAIT or RATELIMIT), we will be able to do so without changing the API again.
If you have your hooks libraries that take advantage of skip flag, migrating to the next step status is very easy. See The Next step status for detailed explanation of the new status field.
To migrate, replace this old code:
with this:
Although the Kea modules can be characterized as handling a single packet at a time - e.g., the DHCPv4 server receives a DHCPDISCOVER packet, processes it and responds with an DHCPOFFER, this may not always be true. Future developments may have the server processing multiple packets simultaneously, or to suspend processing on a packet and resume it at a later time after other packets have been processed.
As well as argument information, the CalloutHandle object can be used by callouts to attach information to a packet being handled by the server. This information (known as "context") is not used by the server: its purpose is to allow callouts to pass information between one another on a per-packet basis.
Context associated with a packet only exists only for the duration of the processing of that packet: when processing is completed, the context is destroyed. A new packet starts with a new (empty) context. Context is particularly useful in servers that may be processing multiple packets simultaneously: callouts can effectively attach data to a packet that follows the packet around the system.
Context information is held as name/value pairs in the same way as arguments, being accessed by the pair of methods setContext and getContext. They have the same restrictions as the setArgument and getArgument methods - the type of data retrieved from context must exactly match the type of the data set.
The example in the next section illustrates their use.
Continuing with the tutorial, the requirements need us to retrieve the hardware address of the incoming packet, classify it, and write it, together with the assigned IP address, to a log file. Although we could do this in one callout, for this example we'll use two:
The standard for naming callouts is to give them the same name as the hook. If this is done, the callouts will be automatically found by the Hooks system (this is discussed further in section Registering Callouts). For our example, we will assume this is the case, so the code for the first callout (used to classify the client's hardware address) is:
The "pkt4_receive" callout placed the hardware address of an interesting client in the "hwaddr" context for the packet. Turning now to the callout that will write this information to the log file:
Hooks libraries take part in the DHCP message processing. They also often modify the server's behavior by taking responsibility for processing the DHCP message at certain stages and instructing the server to skip the default processing for that stage. Thus, hooks libraries play an important role in the DHCP server operation and, depending on their purpose, they may have high complexity, which increases likelihood of the defects in the libraries.
All hooks libraries should use Kea logging system to facilitate diagnostics of the defects in the libraries and issues with the DHCP server's operation. Even if the issue doesn't originate in the hooks library itself, the use of the library may uncover issues in the Kea code that only manifest themselves in some special circumstances.
Hooks libraries use the Kea logging system in the same way as any other standard Kea library. A hooks library should have at least one logger defined, but may have multiple loggers if it is desired to separate log messages from different functional parts of the library.
Assuming that it has been decided to use logging in the hooks library, the implementor must select a unique name for the logger. Ideally the name should have some relationship with the name of the library so that it is easy to distinguish messages logged from this library. For example, if the hooks library is used to capture incoming and outgoing DHCP messages, and the name of the library is "libkea-packet-capture", a suitable logger name could be "packet-capture".
In order to use a logger within the library, the logger should be declared in a header file, which must be included in all files using the logger:
The logger should be defined and initialized in the implementation file, as illustrated below:
These files may contain multiple logger declarations and initializations when the use of more than one logger is desired.
The next step is to add the appropriate message file as described in the Create a Message File.
The implementor must make sure that log messages appear in the right places and that they are logged at the appropriate level. The choice of the place where the message should appear is not always obvious: it depends if the particular function being called already logs enough information and whether adding log message before and/or after the call to this function would simply duplicate some messages. Sometimes the choice whether the log message should appear within the function or outside of it depends on the level of details available for logging. For example, in many cases it is desirable to include the client identifier or transaction id of the DHCP packet being processed in logging message. If this information is available at the higher level but not in the function being called, it is often better to place the log message at higher level. However, the function parameters list could be extended to include the additional information, and to be logged and the logging call made from within the function.
Ideally, the hooks library should contain debug log messages (traces) in all significant decision points in the code, with the information as to how the code hit this decision point, how it will proceed and why. However, care should be taken when selecting the log level for those messages, because selecting too high logging level may impact the performance of the system. For this reason, traces (messages of the debug severity) should use different debug levels for the messages of different importance or having different performance requirements to generate the log message. For example, generation of a log message, which prints full details of a packet, usually requires more CPU bandwidth than the generation of the message which only prints the packet type and length. Thus, the former should be logged at lower debug level (see Message Severity for details of using various debug levels using "dbglevel" parameter).
All loggers defined within the hooks libraries derive the default configuration from the root logger. For example, when the hooks library is attached to the DHCPv4 server, the root logger name is "kea-dhcp4", and the library by default uses configuration of this logger. The configuration of the library's logger can be modified by adding a configuration entry for it to the configuration file. In case of the "packet-capture" logger declared above, the full name of the logger in the configuration file will be "kea-dhcp4.packet-capture". The configuration specified for this logger will override the default configuration derived from the root logger.
Building the code requires building a sharable library. This requires the code be compiled as position-independent code (using the compiler's -fpic switch) and linked as a shared library (with the linker's -shared switch). The build command also needs to point to the Kea include directory and link in the appropriate libraries. Fortunately, the Kea installation holds a kea.pc pkg-config file that provides the necessary include flags -I, library flags -L, and link flags -l.
Assuming that Kea has been installed in the default location, the command line needed to create the library on a Linux system is:
Notes:
The final step is to make the library known to Kea. The configuration keywords of all Kea modules to which hooks can be added contain the "hooks-libraries" element and user libraries are added to this. (The Kea hooks system can handle multiple libraries - this is discussed below.)
To add the example library (assumed to be in /usr/local/lib) to the DHCPv4 module, it must be listed in the "hooks-libraries" element of the "Dhcp4" part of the configuration file:
(Note that "hooks" is plural.)
Each entry in the "hooks-libraries" list is a structure (a "map" in JSON parlance) that holds the following element:
The DHCPv4 server will load the library and execute the callouts each time a request is received.
As well as the hooks defined by the server, the hooks framework defines two hooks of its own, "context_create" and "context_destroy". The first is called when a request is created in the server, before any of the server-specific hooks gets called. It's purpose it to allow a library to initialize per-request context. The second is called after all server-defined hooks have been processed, and is to allow a library to tidy up.
As an example, the "pkt4_send" example above required that the code check for an exception being thrown when accessing the "hwaddr" context item in case it was not set. An alternative strategy would have been to provide a callout for the "context_create" hook and set the context item "hwaddr" to an empty string. Instead of needing to handle an exception, "pkt4_send" would be guaranteed to get something when looking for the hwaddr item and so could write or not write the output depending on the value.
In most cases, "context_destroy" is not needed as the Hooks system automatically deletes context. An example where it could be required is where memory has been allocated by a callout during the processing of a request and a raw pointer to it stored in the context object. On destruction of the context, that memory will not be automatically released. Freeing in the memory in the "context_destroy" callout will solve that problem.
Actually, when the context is destroyed, the destructor associated with any objects stored in it are run. Rather than point to allocated memory with a raw pointer, a better idea would be to point to it with a boost "smart" pointer and store that pointer in the context. When the context is destroyed, the smart pointer's destructor is run, which will automatically delete the pointed-to object.
These approaches are illustrated in the following examples. Here it is assumed that the hooks library is performing some form of security checking on the packet and needs to maintain information in a user-specified "SecurityInformation" object. (The details of this fictitious object are of no concern here.) The object is created in the "context_create" callout and used in both the "pkt4_receive" and the "pkt4_send" callouts.
The requirement for the "context_destroy" callout can be eliminated if a Boost shared ptr is used to point to the allocated memory:
(Note that a Boost shared pointer - rather than any other Boost smart pointer - should be used, as the pointer objects are copied within the hooks framework and only shared pointers have the correct behavior for the copy operation.)
As briefly mentioned in Example Callouts, the standard is for callouts in the user library to have the same name as the name of the hook to which they are being attached. This convention was followed in the tutorial, e.g., the callout that needed to be attached to the "pkt4_receive" hook was named pkt4_receive.
The reason for this convention is that when the library is loaded, the hook framework automatically searches the library for functions with the same names as the server hooks. When it finds one, it attaches it to the appropriate hook point. This simplifies the loading process and bookkeeping required to create a library of callouts.
However, the hooks system is flexible in this area: callouts can have non-standard names, and multiple callouts can be registered on a hook.
The way into the part of the hooks framework that allows callout registration is through the LibraryHandle object. This was briefly introduced in the discussion of the framework functions, in that an object of this type is pass to the "load" function. A LibraryHandle can also be obtained from within a callout by calling the CalloutHandle's getLibraryHandle() method.
The LibraryHandle provides three methods to manipulate callouts:
registerCallout - register a callout on a hook.deregisterCallout - deregister a callout from a hook.deregisterAllCallouts - deregister all callouts on a hook.The following sections cover some of the ways in which these can be used.
The example in the tutorial used standard names for the callouts. As noted above, it is possible to use non-standard names. Suppose, instead of the callout names "pkt4_receive" and "pkt4_send", we had named our callouts "classify" and "write_data". The hooks framework would not have registered these callouts, so we would have needed to do it ourself. The place to do this is the "load" framework function, and its code would have had to been modified to:
It is possible for a library to contain callouts with both standard and non-standard names: ones with standard names will be registered automatically, ones with non-standard names need to be registered manually.
Kea servers natively support a set of control commands to retrieve and update runtime information, e.g. server configuration, basic statistics etc. In many cases, however, DHCP deployments require support for additional commands or the natively supported commands don't exactly fulfill one's requirements.
Taking advantage of Kea's modularity and hooks framework, it is now possible to easily extend the pool of supported commands by implementing additional (non-standard) commands within hook libraries.
A hook library needs to register command handlers for control commands within its load function as follows:
Internally, the LibraryHandle associates command handlers diagnostics_enable and diagnostics_dump with dedicated hook points. These hook points are given names after the command names, i.e. "$diagnostics_enable" and "$diagnostics_dump". The dollar sign before the hook point name indicates that the hook point is dedicated for a command handler, i.e. is not one of the standard hook points used by the Kea servers. This is just a naming convention, usually invisible to the hook library implementation and is mainly aimed at minimizing a risk of collision between names of the hook points registered with command handlers and standard hook points.
Once the hook library is loaded and the command handlers supported by the library are registered, the Kea servers will be able to recognize that those specific commands are supported and will dispatch commands with the corresponding names to the hook library (or multiple hook libraries) for processing. See the documentation of the isc::config::HookedCommandMgr for more details how it uses HooksManager::commandHandlersPresent to determine if the received command should be dispatched to a hook library for processing.
The diagnostics_enable and diagnostics_dump command handlers must be implemented within the hook library in analogous way to regular callouts:
The sample code above retrieves the "command" argument which is always provided. It represents the control command as sent by the controlling client. It includes command name and command specific arguments. The generic isc::config::parseCommand can be used to retrieve arguments included in the command. The callout then interprets these arguments, takes appropriate action and creates a response to the client. Care should be taken to catch any non-fatal exceptions that may arise during the callout that should be reported as a failure to the controlling client. In such case, the response with CONTROL_RESULT_ERROR is returned and the callout should return the value of 0. The non-zero result should only be returned by the callout in case of fatal errors, i.e. errors which result in inability to generate a response to the client. If the response is generated, the command handler must set it as "response" argument prior to return.
It is uncommon but valid scenario to have multiple hook libraries providing command handlers for the same command. They are invoked sequentially and each of them can freely modify a response set by a previous callout. This includes entirely replacing the response provided by previous callouts, if necessary.
The Kea hooks framework allows multiple callouts to be attached to a hook point. Although it is likely to be rare for user code to need to do this, there may be instances where it make sense.
To register multiple callouts on a hook, just call LibraryHandle::registerCallout multiple times on the same hook, e.g.,
The hooks framework will call the callouts in the order they are registered. The same CalloutHandle is passed between them, so any change made to the CalloutHandle's arguments, "skip" flag, or per-request context by the first is visible to the second.
As alluded to in the section Configuring the Hooks Library, Kea can load multiple libraries. The libraries are loaded in the order specified in the configuration, and the callouts attached to the hooks in the order presented by the libraries.
The following picture illustrates this, and also illustrates the scope of data passed around the system.
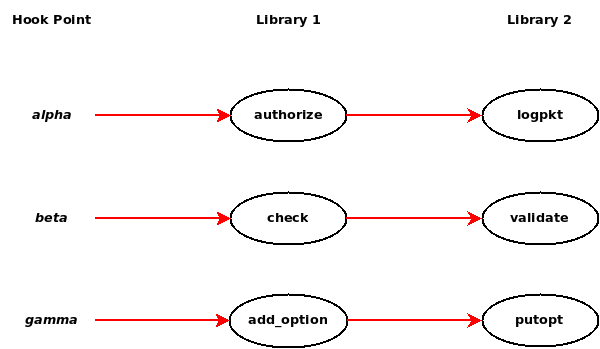
In this illustration, a server has three hook points, alpha, beta and gamma. Two libraries are configured, library 1 and library 2. Library 1 registers the callout "authorize" for hook alpha, "check" for hook beta and "add_option" for hook gamma. Library 2 registers "logpkt", "validate" and "putopt"
The horizontal red lines represent arguments to callouts. When the server calls hook alpha, it creates an argument list and calls the first callout for the hook, "authorize". When that callout returns, the same (but possibly modified) argument list is passed to the next callout in the chain, "logpkt". Another, separate argument list is created for hook beta and passed to the callouts "check" and "validate" in that order. A similar sequence occurs for hook gamma.
The next picture shows the scope of the context associated with a request.
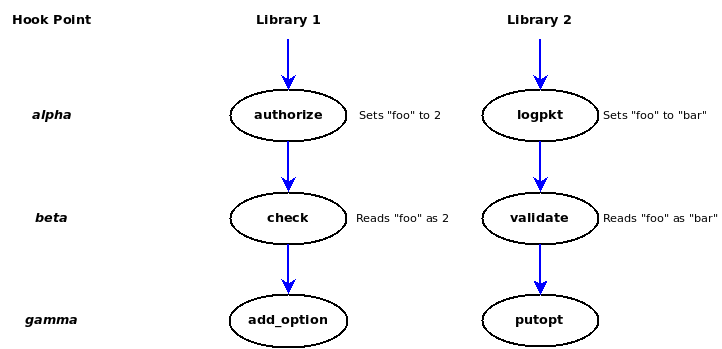
The vertical blue lines represent callout context. Context is per-packet but also per-library. When the server calls "authorize", the CalloutHandle's getContext and setContext methods access a context created purely for library 1. The next callout on the hook will access context created for library 2. These contexts are passed to the callouts associated with the next hook. So when "check" is called, it gets the context data that was set by "authorize", when "validate" is called, it gets the context data set by "logpkt".
It is stressed that the context for callouts associated with different libraries is entirely separate. For example, suppose "authorize" sets the CalloutHandle's context item "foo" to 2 and "logpkt" sets an item of the same name to the string "bar". When "check" accesses the context item "foo", it gets a value of 2; when "validate" accesses an item of the same name, it gets the value "bar".
It is also stressed that all this context exists only for the life of the request being processed. When that request is complete, all the context associated with that request - for all libraries - is destroyed, and new context created for the next request.
This structure means that library authors can use per-request context without worrying about the presence of other libraries. Other libraries may be present, but will not affect the context values set by a library's callouts.
Configuring multiple libraries just requires listing the libraries as separate elements of the hooks-libraries configuration element, e.g.,
In rare cases, it is possible that one library may want to pass data to another. This can be done in a limited way by means of the CalloutHandle's setArgument and getArgument calls. For example, in the above diagram, the callout "add_option" can pass a value to "putopt" by setting a name.value pair in the hook's argument list. "putopt" would be able to read this, but would not be able to return information back to "add_option".
All argument names used by Kea will be a combination of letters (both upper- and lower-case), digits, hyphens and underscores: no other characters will be used. As argument names are simple strings, it is suggested that if such a mechanism be used, the names of the data values passed between the libraries include a special character such as the dollar symbol or percent sign. In this way there is no danger that a name will conflict with any existing or future Kea argument names.
If Kea is built with the "-D default_library=static" switch (set when running the "meson setup" script), no shared Kea libraries are built; instead, archive libraries are created and Kea is linked to them. If you create a hooks library also linked against these archive libraries, when the library is loaded you end up with two copies of the library code, one in Kea and one in your library.
To run successfully, your library needs to perform run-time initialization of the Kea code in your library (something performed by Kea in the case of shared libraries). To do this, call the function isc::hooks::hooksStaticLinkInit() as the first statement of the load() function. (If your library does not include a load() function, you need to add one.) For example:
Sometimes it is useful for the hook library to have some configuration parameters. This capability was introduced in Kea 1.1. This is often convenient to follow generic Kea configuration approach rather than invent your own configuration logic. Consider the following example:
This example has three hook libraries configured. The first and second have no parameters. Note that parameters map is optional, but it's perfectly okay to specify it as an empty map. The third library is more interesting. It has five parameters specified. The first one called 'mail' is a string. The second one is an integer and the third one is boolean. Fourth and fifth parameters are slightly more complicated as they are a list and a map respectively. JSON structures can be nested if necessary, e.g., you can have a list, which contains maps, maps that contain maps that contain other maps etc. Any valid JSON structure can be represented. One important limitation here is that the top level "parameters" structure must either be a map or not present at all.
Those parameters can be accessed in load() method. Passed isc::hooks::LibraryHandle object has a method called getParameter that returns an instance of isc::data::ConstElementPtr or null pointer if there was no parameter specified. This pointer will point to an object derived from isc::data::Element class. For detailed explanation how to use those objects, see isc::data::Element class.
Here's a brief overview of how to use those elements:
Keep in mind that the user can structure his config file incorrectly. Remember to check if the structure has the expected type before using type specific method. For example calling stringValue on IntElement will throw an exception. You can do this by calling isc::data::Element::getType.
Here's an example that obtains all of the parameters specified above. If you want to get nested elements, Element::get(index) and Element::find(name) will return ElementPtr, which can be iterated in similar manner.
A good sources of examples could be unit-tests in file src/lib/cc/tests/data_unittests.cc which are dedicated to isc::data::Element testing and src/lib/hooks/tests/callout_params_library.cc, which is an example library used in testing. This library expects exactly 3 parameters: svalue (which is a string), ivalue (which is an integer) and bvalue (which is a boolean).
Both Kea server memory space and hook library memory space share a common address space between the opening of the hook (call to dlopen() as the first phase of the hook library loading) and the closing of the hook (call to dlclose() as the last phase of the hook library unloading). There are pointers between the two memory spaces with at least two bad consequences when they are not correctly managed:
Communication between Kea code and hook library code is provided by callout handles. For callout points related to a packet, the callout handle is associated with the packet allowing to get the same callout handle for all callout points called during processing of a query.
Hook libraries are closed i.e. hook library memory spaces are unmapped only when there is no active callout handles. This enforces a correct behavior at two conditions:
To allow hook writers to fulfill these two conditions the unload() entry point is called in the first phase of the unloading process since Kea version 1.7.10. For instance if the hook library uses the PIMPL code pattern the unload() entry point must reset the pointer to the hook library implementation.
Multi-threading programming in C++ is not easy. For instance STL containers do not support simultaneous read and write accesses. Kea is written in C++ so a priori for all Kea APIs one should never assume thread safety.
When a hook library is internally multi-threaded, its code and any Kea API used simultaneously by different threads must be thread safe. To mark the difference between this and the other thread safety requirement this is called "generic thread safe".
When multi-threaded packet processing is enabled, Kea servers perform some actions by the main thread and packet processing by members of a thread pool. The multi-threading mode is returned by:
When it is false, Kea is single threaded and there is no thread safety requirement, when it is true, the requirement is named Kea packet processing thread safe shorten into "Kea thread safe".
A typical Kea thread safe looks like:
The overhead of mutexes and other synchronization tools is far greater than a test and branch so it is the recommended way to implement Kea thread safety.
When a hook library entry point can be called from a packet processing thread, typically from a packet processing callout but also when implementing a lease or host backend API, the entry point code must be Kea thread safe. If it is not possible the hook library must be marked as not multi-threading compatible (i.e. return 0 from multi_threading_compatible).
At the opposite during (re)configuration including libload command and config backend, only the main thread runs, so version, load, unload, multi_threading_compatible, dhcp4_srv_configured, dhcp6_srv_configured, cb4_updated and cb6_updated have no thread safety requirements.
Other hook library entry points are called by the main thread:
The packet processing threads are not stopped so either the entry point code is Kea thread safe or it uses a critical section (isc::util::MultiThreadingCriticalSection) to stop the packet processing threads during the execution of the not Kea thread safe code. Of course critical sections have an impact on performance so they should be used only for particular cases where no better choice is available.
Some Kea APIs were made thread safe mainly because they are used by the packet processing:
Some other Kea APIs are intrinsically thread safe because they do not involve a shared structure so for instance despite of its name the interface manager send methods are generic thread safe.
Per library documentation details thread safety to help hooks writers and to provide an exhaustive list of Kea thread safe APIs: